











Über dieses Audioangebot & Ihr Feedback
Die Audioversion dieses Artikels wurde künstlich erzeugt. Wir entwickeln dieses Angebot stetig weiter und freuen uns über Ihr Feedback.

Dual-Track Agile ist ein leistungsfähiges Werkzeug für komplexe Aufgabenstellungen, bei denen der Lösungsweg kontinuierlich weiterentwickelt oder sogar verändert wird. Die Methodik verbindet zwei eng miteinander verzahnte Prozesse: Discovery, d.h. Lösungsmöglichkeiten entdecken und Delivery, d.h. einsatzbereite Software liefern. Anhand eines Data-Analytics-Projekts beschreiben Katharina Gossen und Christoph Jung, wie sie die Teams für Discovery und Delivery integrierten, die Planung auf mehreren Ebenen organisierten und das Zusammenspiel der beiden Tracks überwachten und steuerten. Wer Dual-Track Agile einsetzen will, sollte aber die erforderlichen Voraussetzungen mitbringen.
Als Mitglied erhalten Sie die wichtigsten Thesen des Beitrags zusammengefasst im Management Summary!
Dual-Track Agile ist ein leistungsfähiges Werkzeug für komplexe Aufgabenstellungen, bei denen der Lösungsweg kontinuierlich weiterentwickelt oder sogar verändert wird. Die Methodik verbindet zwei eng miteinander verzahnte Prozesse: Discovery, d.h. Lösungsmöglichkeiten entdecken und Delivery, d.h. einsatzbereite Software liefern. Anhand eines Data-Analytics-Projekts beschreiben Katharina Gossen und Christoph Jung, wie sie die Teams für Discovery und Delivery integrierten, die Planung auf mehreren Ebenen organisierten und das Zusammenspiel der beiden Tracks überwachten und steuerten. Wer Dual-Track Agile einsetzen will, sollte aber die erforderlichen Voraussetzungen mitbringen.
Als Mitglied erhalten Sie die wichtigsten Thesen des Beitrags zusammengefasst im Management Summary!
Dual-Track Agile dient bei agilen Produktentwicklungen mit hohem Unsicherheitsgrad bzw. hohem Forschungsanteil dazu, eine Balance zwischen Experimentieren und Entwicklung zu finden. Nur aussichtsreich erscheinende Lösungsansätze werden für die Umsetzung ausgewählt, wodurch die Entwicklung effizienter wird. In unserem Artikel beschreiben wir, wie wir Dual-Track Agile in einem Data Analytics Projekt umsetzten.
Bei unserem Projekt im Bereich Data Analytics ging es um die Verbesserung von datenbasierten Vorhersagen (siehe Anhang: Was macht ein Data-Analytics-Projekt aus?). Dabei ist das Vorgehen prinzipiell nicht von Anfang bis Ende planbar – es gibt Unsicherheiten mit denen man umgehen muss: Geeignete Datenquellen auszuwählen und zu bewerten, Muster und Regelmäßigkeiten in den Daten zu erkennen und Modelle zu entwickeln. Erst im Anschluss daran kann entschieden werden, welche Modelle vielversprechend sind und weiterentwickelt werden sollen. In diesem explorativen Prozess verschieben sich die Schwerpunkte häufig zwischen Analysieren, Forschen, Entwickeln, Testen und Liefern.
Die Vision des hier beschriebenen Data-Analytics-Projekts war: "Wir entwickeln ein neues Vorhersagemodell, das auf Basis der historischen und aktuellen Daten in Echtzeit verlässliche Prognosen für zukünftige Ereignisse berechnet."
Die möglichen Anwendungen für Data Analytics sind vielfältig. Einige mögliche Beispiele aus unterschiedlichen Bereichen sollen dies illustrieren: Täglich schicken Paketdienste millionenfach ihren Kunden Prognosen zum wahrscheinlichen Liefertermin eines Pakets zu. Mit Hilfe von Data Analytics (bzw. Machine Learning) könnten hierfür so früh und genau wie möglich die Liefertermine vorhergesagt werden, damit die Empfänger sich rechtzeitig darauf einstellen können. Die Ankunftszeiten von Flugzeugen, die Auslastung von Stromnetzen und das Bestellverhalten in Online-Kaufhäusern sind weitere anschauliche Beispiele für die Anwendung von Echtzeitprognosen.
In einem Prognoseverfahren geht es darum, aus den vorhandenen Daten Vorhersagen für ein zukünftiges Ereignis zu treffen. Wie gut diese Vorhersagen sind, hängt vor allem von der Qualität und Verfügbarkeit der Daten ab, die das zukünftige Ereignis beeinflussen können, von der Qualität der Vorhersagemodelle, die zur Berechnung der Prognose herangezogen werden, sowie von der Verfügbarkeit von historischen Daten.
Als Basis dienen historische und aktuelle Daten aus dem Unternehmen und dem Unternehmensumfeld. Diese Daten werden gesammelt, aufbereitet, analysiert und in einem Vorhersagemodell kombiniert. Dabei kommen oft Big-Data-Technologien und Machine-Learning-Ansätze zum Einsatz. Bei letzterem lernt das System aus der Vergangenheit, indem es Muster und Zusammenhänge in den vorhandenen Daten erkennt (durch Optimierung von Modellparametern).
Das zu entwickelnde System sollte neue sowie bereits im Unternehmen verfügbare Datenquellen zusammenführen und anschließend mehrere Millionen Prognosen pro Tag in Echtzeit erzeugen. Dies sollte u.a. mit Hilfe von Big-Data-Technologien und Machine Learning erfolgen. Es war geplant, zuerst ein Basissystem einzuführen, das anschließend schrittweise erweitert werden sollte, z.B. durch Hinzufügen neuer Datenquellen und neuer Vorhersagemodelle. Die Potentiale der Daten und Modelle, die man daraus entwickeln konnte, waren am Anfang aber noch unbekannt und mussten zuerst erforscht werden.
Als das Basissystem entwickelt war, standen wir vor den folgenden Herausforderungen:
Das Basissystem hatte ein externer Partner entwickelt, der in einer aufwendigen Vorstudie (mit Prototyp-Lösungen) aus zahlreichen Wettbewerbern ausgewählt worden war. Die Erkenntnisse der Vorstudie halfen, das grundlegende Vorgehen mit dem ausgewählten Partner zu bestimmen. Es wurde jedoch schnell klar, dass bei diesem Projekt kontinuierlich weiter geforscht (und gelernt) werden musste.
Das Projekt war zunächst traditionell aufgesetzt: Anforderungsanalyse, umfangreiche Beschreibung des Auftrags, Entwicklungsphase, Abnahmetest und am Ende die Einführung des Systems. Die Idee war, dass der Auftraggeber die fachliche Steuerung übernimmt und vor allem an weiteren Daten und Modellen forscht. Der Auftragnehmer entwickelt und bringt die Funktionalität zum Kunden.
Diese Trennung der Aufgaben führte jedoch mit der Zeit zur Bildung von Silos: Zum einen gab es eine spürbare Barriere zwischen Auftragnehmer und Auftraggeber, u.a. durch vertragliche Vorgaben oder fehlenden Zugang zu Wissen. Zum anderen entstanden zwei parallele System-Welten, die jeweils entwickelt, getestet, gewartet und natürlich bezahlt werden mussten.
Die Forschung auf Seiten des Auftraggebers erfolgte mehr oder weniger im Hintergrund, da der Fokus auf der Einführung des Basissystems lag. Dies führte dazu, dass nicht für alle Beteiligten immer transparent war, woran das Forschungsteam arbeitete, welche Hypothesen es verfolgte und wie groß die Potentiale der jeweiligen Hypothesen waren.
Die Parallelwelten erschwerten es auch, Ergebnisse aus dem Forschungsbereich schnell in die Umsetzung und zum Kunden zu bringen. Was im Labor des einen Teams mit dessen Prototyp funktionierte, war nicht eins zu eins auf die Entwicklungsstrecke des anderen Teams übertragbar und musste dort erst verstanden sowie in dessen Prototyp transformiert werden.
Auf der Suche nach einer agilen Vorgehensweise, mit der wir genau diese Herausforderungen in unserem Projekt angehen konnten, stießen wir auf das Konzept "Dual-Track Agile" (auch "Dual-Track Scrum" oder "Dual-Track Development" genannt).
Dual-Track Agile sieht vor, dass parallel zur inkrementellen Software-Entwicklung eine kontinuierliche und frühe Validierung neuer Ideen bzw. Hypothesen erfolgt. In einer Entwicklungs-Iteration (z.B. einem Sprint in Scrum) laufen somit zwei Prozesse ab, die eng miteinander verzahnt sind: Discovery, d.h. Lösungsmöglichkeiten entdecken sowie Hypothesen validieren und Delivery, d.h. Software entwickeln und liefern (Bild 1). Das ursprüngliche Konzept stammt von Desirée Sy (Sy, 2007), die diese beiden Prozesse als "Tracks" bezeichnete. Danach wurde es u.a. durch Jeff Patton (Patton, 2017) weiter bekannt.
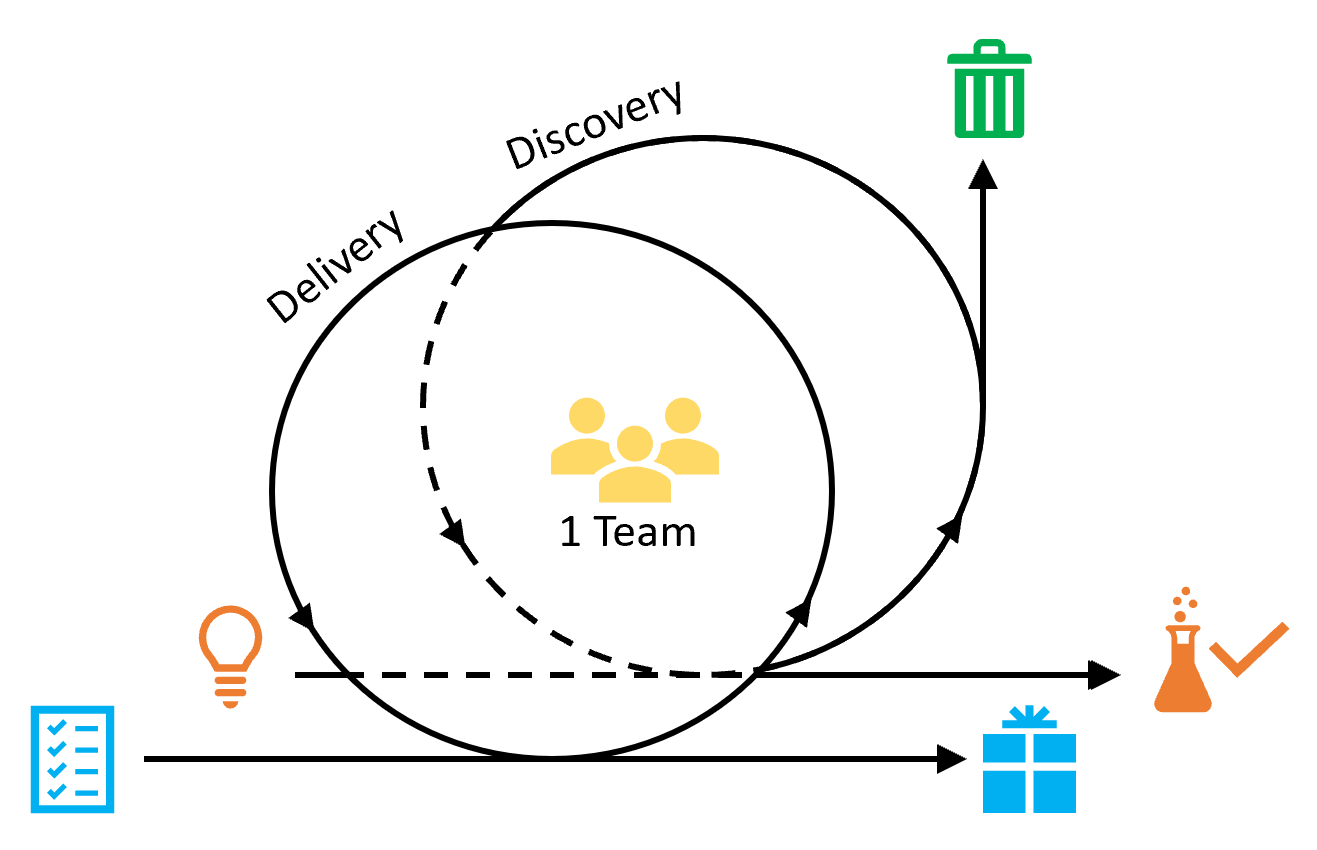
Der Discovery Track ist ein kreativer und explorativer Prozess, bei dem man viel ausprobiert, schnell viele Prototypen generiert und testet, dann aber auch viel wieder verwirft, was nicht erfolgreich war. Entscheidend ist, dass es sich um einen kontinuierlichen, iterativen Prozess handelt, bei dem Ideen laufend erfasst, priorisiert und evaluiert werden. Bei Produktentwicklungen kann man dazu z.B. einfache Papier-Prototypen des Produkts verwenden, um sie mit Anwendern zu testen.
Das Ziel ist, Hypothesen schnell und günstig zu bewerten und nicht zielführende Ansätze so weit wie möglich herauszufiltern, sodass nur die vielversprechendsten Ansätze ans Delivery übergeben werden. Dadurch liefert der Discovery Track kontinuierlich validierte Features für die folgende Entwicklung und ggf. auch neue Hypothesen zur erneuten Analyse.
Gleichzeitig werden im Delivery Track die zuvor validierten Hypothesen aus dem Discovery Track inkrementell und iterativ in Software umgesetzt. Das muss aber nicht bedeuten, dass jede validierte Hypothese automatisch an Kunden ausgeliefert wird. In der Regel werden im Delivery Track die Ergebnisse weiter validiert. Die Erkenntnisse aus dem Delivery Track (z.B. Statistiken darüber, wie häufig bestimmte Funktionen der Software benutzt werden) werden zurück an den Discovery Track gespiegelt und somit bei der Validierung von neuen Ideen berücksichtigt.
Die Kunst liegt darin, Discovery- und Delivery-Arbeit in einem Team sinnvoll auszubalancieren. Ein wichtiger Aspekt von Dual-Track Agile ist hierbei, dass beide Prozesse im selben interdisziplinären Team ablaufen müssen, um den Wissensaustausch zu optimieren. D.h. Dual-Track bedeutet nicht "Dual-Team"!
In der agilen Produktentwicklung – wo Dual-Track ja seine Wurzel hat – stellt sich oft die Frage: "Wie kann ich mir mit wenig Aufwand sicher sein, dass die Benutzer diese Funktionalität brauchen?". In unserem Kontext liegt die Unsicherheit nicht bei den unbekannten Bedürfnissen der Benutzer, sondern bei den unbekannten Potentialen in unseren Daten. Hier lautet die Frage dann: "Wie kann ich mir sicher sein, dass diese Datenquelle und diese Regelmäßigkeiten meine Prognose verbessern?"
Da Dual-Track Agile in der Produktentwicklung einen sinnvollen Umgang mit Unsicherheit bzgl. Anforderungen bietet, nahmen wir an, dass es uns auch hilft, mit der Unsicherheit bei der Erschließung von Daten und datengetriebener Wertschöpfung umzugehen. Deshalb entschieden wir uns, den Ansatz in unserem Projekt auszuprobieren.
In den folgenden Kapiteln beschreiben wir, wie wir Dual-Track Agile bei uns umsetzten:
Zum Schluss benennen wir die aus unserer Erfahrung notwendigen Voraussetzungen für den Einsatz von Dual-Track Agile.
pro Monat, bei jährlicher Zahlung im ersten Jahr, danach 24,99 € pro Monat. Code SOMMERPROJEKT im Checkout eingeben.